Selected Publications
ijtiff: An R Package Providing Comprehensive TIFF I/O
General purpose TIFF file I/O for R users. This is currently the only such package with read and write support for TIFF files with floating point (real-numbered) pixels, and the only package that can correctly import TIFF files that were saved from ‘ImageJ’ and write TIFF files than can be correctly read by ‘ImageJ’ https://imagej.nih.gov/ij/. Also supports text image I/O.
In JOSS,
2018
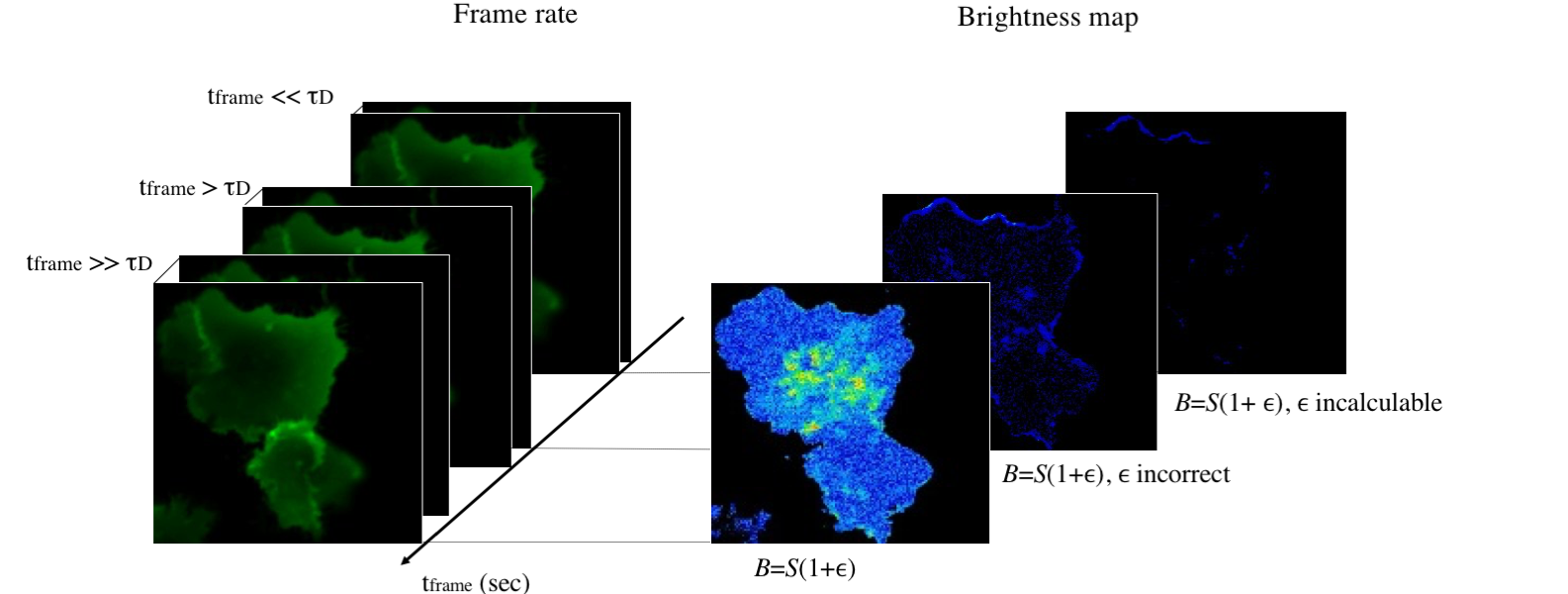
Detecting Protein Aggregation and Interactions in Live Cells: a Guide to Number and Brightness
The possibility to detect and quantify protein-protein interactions with good spatial and temporal resolutions in live cells is crucial in biology. Number and brightness is a powerful approach to detect both protein aggregation/desegregation dynamics and stoichiometry in live cells. Importantly, this technique can be applied in commercial set ups: both camera based and laser scanning microscopes. It provides pixel-by-pixel information on protein oligomeric states. If performed with two colours, the technique can retrieve the stoichiometry of the reaction under study. In this review, we discuss the strengths and weaknesses of the technique, stressing which are the correct acquisition parameters for a given microscope, the main challenges in analysis, and the limitations of the technique.
In Methods,
2017
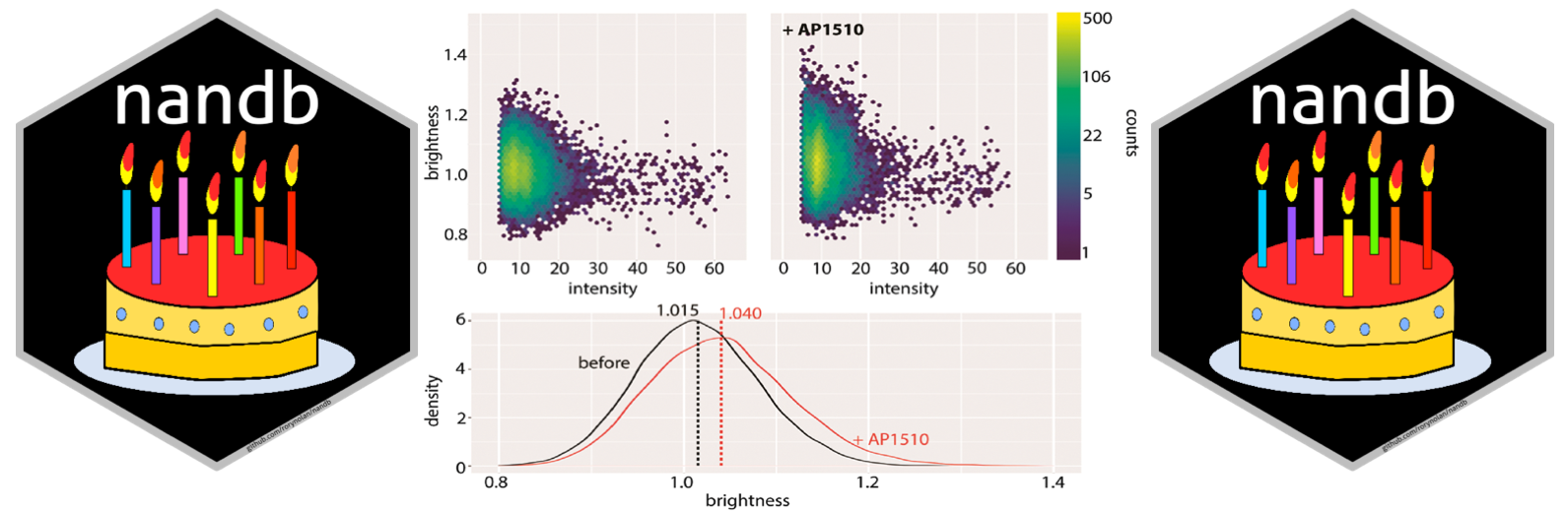
nandb — Number and Brightness in R with a Novel Automatic Detrending Algorithm
An R package for performing number and brightness image analysis, with the implementation of a novel automatic detrending algorithm.
In Bioinformatics,
2017